8/20/17
Wrote this for an in-person overview of data science for a group of ambitious highschoolers
We see it take place in our daily lives:
- Facebook friend recommender via triangle closing recommender system based on graph theory e.g. Gina’s friends with Jackie, Jackie’s friends with Ryan, Ryan will be recommended.
- Snapchat’s puppy dog filter via eyes and nose recognition using deeplearning.
- Tinder’s smart photos via multi-arm bandit algorithm.
How’s it used at Rocketrip:
- parsing receipts/images
- figuring out the impact of the actual product on the companies revenue
- auto approving points / fraud detection
- pricing budgets
- segmenting the customer base etc.
Cool concepts not yet developed:
Predict how many likes you’ll get from an instagram post.
Steps
-
Show it makes money: Find business value of creating such a product. Instagram influencers are usually paid by some company to post about their products so a tool like this could come in handy.
-
Identify relevant data points:
target variable (aka labels): number of likes features (things which could influence "number of likes"): number of followers number of people following pictures number of past posts text from the postsMost of time websites offer api’s which is a portal into their database and if this service isn’t available, you’ll have to make a screen-scraper (data mining bot on targeted websites).
-
Exploration: The goal here is to poke around and understand the nuances of the data and make adjustments accordingly. For example, we noticed that there are some celebrities/stars whose post get an inordinate amount of attention for reasons that don’t have anything to do with the post itself i.e. publics spectacle appeal.
- summary statistics e.g. averages, total counts, number of missing data, etc
-
visualization of data e.g. plotting the number of followers vs number of likes to see if there’s any correlation.
-
Prepare data for input to the model (preprocessing): Machine learning models only understand numbers as input. As such, we have to find the proper way to transform raw data i.e. an entire instagram post and all the different types of data to numerical form.
For text data
- count the number of times a certain emoji appears
- count number of times a certain work occurs
- number of tags etc
Pictures
- count the number of people in the picture
- brightness
- the shade of a certain color in a picture e.g. red. etc
Explicit features Usually offered straight-up and involve no special tooling for extraction.
- the user’s number of followers
- number of past posts etc
-
Now we can train the model:
i) Model selection
Appropriate for the problem at hand the basic families evolves as follows: Statistical models, Machine Learning, Artificial Intelligence. E.g. Linear regression, Gradient boosting, Convolutional Neural Net.
ii) Train the model
Model’s train on “examples” of the problem at hand. So think about how you prepare for a math test. You study some examples with the solution at hand. You might try a few without knowing the answer beforehand just to verify you understand the concept… After a few rounds of this you’ll feel confident to take a test where you won’t be shown the answer. Same thing applies for training an ML model.
This post with 3 emojis, the word "banana" showed up 3 times, 1 very bright photo,.... got about 40 likes.iii) Prediction
You’ll keep on training the model with with the information above and eventually the model will uncover a pattern and it’ll get very good at guessing the number of likes a post will get given it’s features (attributes).
- Productionization: How to make the model and it’s predictive powers accessible to the rest of the world. Indepth blog on the approach
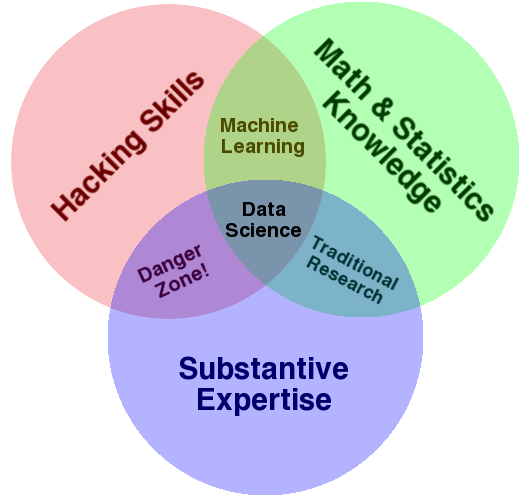
What skills do you need?
The Venn diagram below does a fairly accurate job of showing what’s foundational to get into the field. Depending on the nature of the role itself might be more of one circle(e.g. engineering) or the other.